
大模型不懂命理,但她们还是问了
大模型不懂命理,但她们还是问了年初,DeepSeek 上线,18 天内即获得了 1600 万次下载,登顶 140 国下载榜单。让人意料之外而又情理之中的是,AI最火的功能不是翻译、写作,而是算命。有数据显示,#DeepSeek 算命等话题在小红书上吸引了超过 6600 万次浏览。
来自主题: AI资讯
10625 点击 2025-04-27 20:38
 搜索
搜索
年初,DeepSeek 上线,18 天内即获得了 1600 万次下载,登顶 140 国下载榜单。让人意料之外而又情理之中的是,AI最火的功能不是翻译、写作,而是算命。有数据显示,#DeepSeek 算命等话题在小红书上吸引了超过 6600 万次浏览。
在DeepSeek R1-V3、GPT-4o、Claude-3.7的强势围攻下,Meta坐不住了。曾作为开源之光的Llama在一年的竞争内连连失利,并没有研发出让公众惊艳的功能。创始人扎克伯格下达死命令,今年4月一定要更新。
新芒xAI今天注意到,备受关注的全球顶级域名 AI.com 跳转目标近日发生变更。目前访问 AI.com 会跳转至一个全新的、充满神秘感的网站。此前该域名曾指向人工智能初创公司 DeepSeek 的相关页面,但根据最新观察,AI.com 现已解绑 DeepSeek。

最近,我撞见了一个 DeepSeek 又“认真”又“拧巴”的怪异场景。

2025开年伊始,从1月DeepSeek R1发布引发新一轮国产大模型技术爆发,到3月Manus横空出世启动内测打开AI智能体话题热度,从底层基础设施到终端产品应用,从产业深耕提升纵深能力到产品创新形成差异化竞争优势,无论是技术能力还是商业模式,国产AI都处于全球领先水平。海外无论是政策环境还是供需关系,均从内外部双轮驱动国产AI出海蓄势待发。
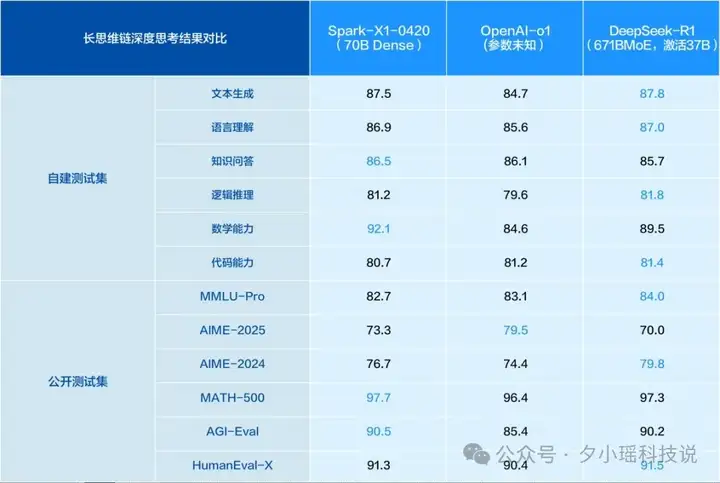
就在昨天,深耕语音、认知智能几十年的科大讯飞,发布了全新升级的讯飞星火推理模型 X1。不仅效果上比肩 DeepSeek-R1,而且我注意到一条官方发布的信息——基于全国产算力训练,在模型参数量比业界同类模型小一个数量级的情况下,整体效果能对标 OpenAI o1 和 DeepSeek R1。
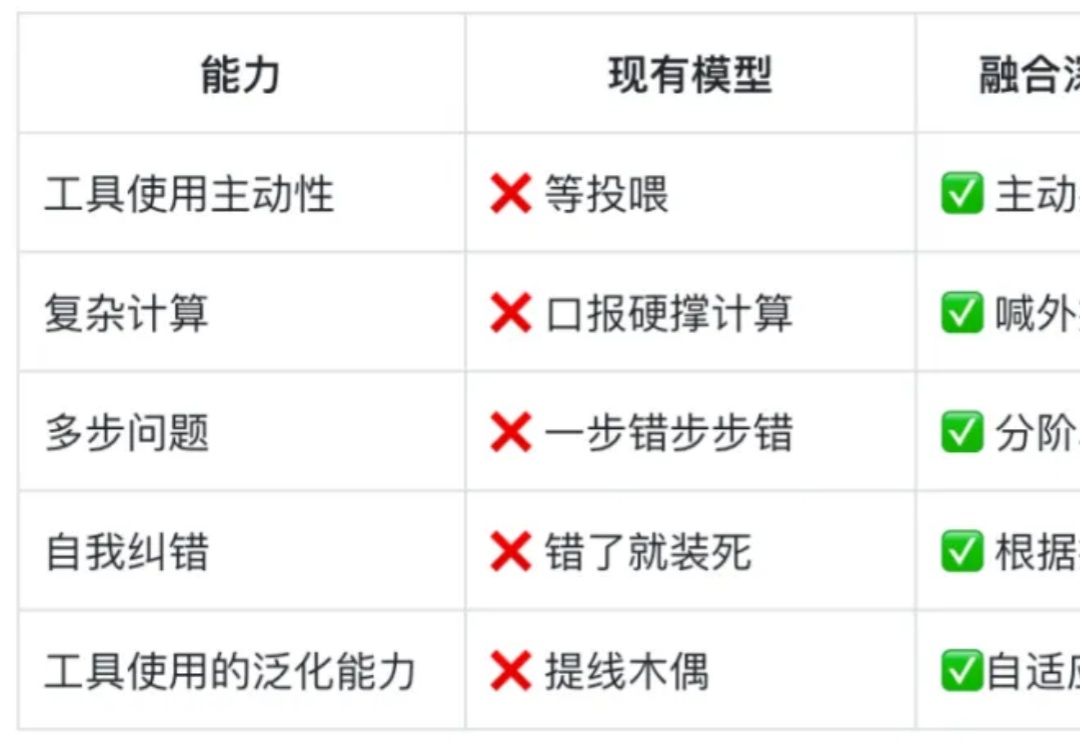
GPT - 4o、Deepseek - R1 等高级模型已展现出令人惊叹的「深度思考」能力:理解上下文关联、拆解多步骤问题、甚至通过思维链(Chain - of - Thought)进行自我验证、自我反思等推理过程。

继接入 DeepSeek 后,APPSO 发现名为「元宝」的 AI 助手目前已经正式入驻微信。现在,你可以在微信框搜索「元宝」,亦或者直接扫描二维码图片,将其添加到通讯录,即可与它展开对话。

2024 年,是学习平板这个品类集中爆发的一年。
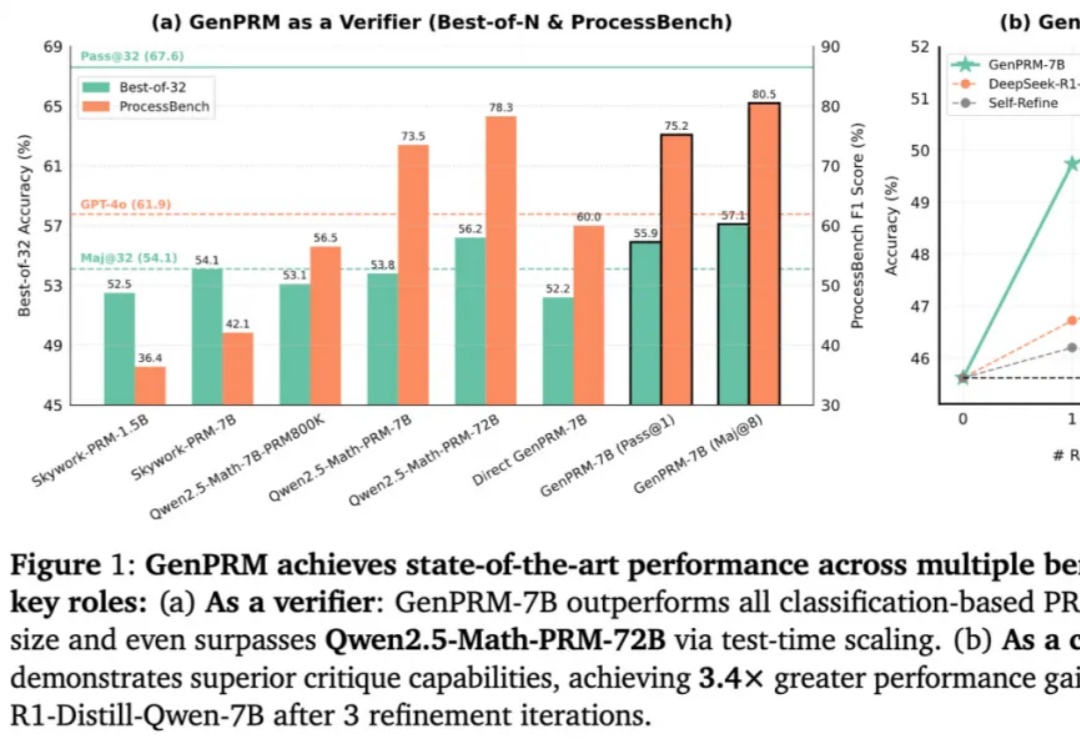
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。